Dynamic Model-Building: A Proposed Variable Selection Algorithm
Existing model-building procedures tend to work well for specific model setups such as credit scorecard-building. However, when it comes to creating dynamic credit risk models that are linked to macroeconomic as well as portfolio characteristics, most routines fall short in selecting a model that suits the analyst’s targets. Scenario-conditional forecasting and stress testing models are a clear example where current state-of-the-art selection methods fail to achieve the main purposes of the exercise: producing coherent scenario spreading, handling the computation of sensitivities of macroeconomic series, considering time-series properties of residuals, achieving target forecasting accuracy, and more.
In this article, we propose an innovative algorithm that is well suited to building dynamic models for credit and market risk metrics, consistent with regulatory requirements around stress testing, forecasting, and IFRS 9. Our method combines economic intuition, statistical rigor, and computational efficiency. We compare the results of the algorithm with standard industry best practice procedures such as stepwise and LASSO and demonstrate its advantages.
Introduction
Modern stress testing exercises require explicit links between market and credit risk metrics with core macroeconomic variables. Such linkages can be established using various econometric techniques that must comply with regulatory requirements, including those of the US Federal Reserve, the UK Prudential Regulation Authority (PRA), and the European Banking Authority (EBA). Such requirements include the timing and magnitude of a response of the modeled metrics to hypothetical macroeconomic shocks.1
In this article, we propose an innovative algorithm that is well-suited to building dynamic models for credit and market risk metrics, consistent with regulatory requirements around stress testing, forecasting, and International Financial Reporting Standard 9 (IFRS 9). Our method consists of three main steps that combine economic intuition (macro constraints), statistical rigor when selecting model drivers, and computational efficiency to find an optimal parsimonious model with strong in-sample fit and forecasting properties. The user can select a subset of potential macroeconomic drivers and run the customized best-subset selection algorithm to choose the optimal combination (and lags) among these candidates. The selected model is then diagnosed and validated to ensure it is satisfactory for stress testing. This paper also demonstrates the methodology used by Moody’s Analytics to design models in line with the regulatory requirements, and shows its application to selected market risk metrics.2
To set up a model, one needs to find the optimal combination of explanatory variables to forecast a target risk metric. A good model compliant with regulatory demands should include all important drivers, while still being parsimonious, suitable for forecasting, easily interpretable, and in line with economic theory. Practitioners often have to model risk factors for which standard theoretical models abstract from world complexity. Thus, the vector of drivers suggested by economic theory must be extended to include other potential variables that capture market interconnectedness, spillover effects, and other potential determinants. In many cases, historical data and statistical analyses help select what additional variables to keep in models. The variable selection method we describe here is not pure machine learning but is customized to combine economic intuition, the model developer’s experience, and historical data analysis.
The model-building procedure that we often use at Moody’s Analytics consists of three steps. First, we select potential drivers of the target risk metric that are likely to be the most important based on economic intuition, experience with similar models, and historical data analysis. Second, we run a customized variable selection algorithm to choose the optimal combination of drivers. Finally, the subset of likely models is diagnosed and validated to identify a handful of the best-performing forecast models. The model developer can then select an optimal model satisfactory for stress testing.3
One of the key building blocks of this procedure is the best-subset selection algorithm. It first chooses the subset of likely models according to the user-defined correlation and selection criteria. These criteria may include the prior expectations on correlations between the drivers, the estimated signs (based on economic intuition), and a threshold on the statistical significance. The resulting subset of candidate models is then sorted according to ranking criteria that include various measures of in-sample fit and predictive ability.
This paper is structured as follows. In the first section, we discuss key existing variable selection algorithms. The following section shows Moody’s Analytics approach to building a typical model for stress testing. The last section demonstrates the model selection algorithms using the examples of option-adjusted corporate spreads and UK government bond yields.
Variable Selection Algorithms
The most commonly used automatic variable selection algorithms include subset selection, stepwise regression, and shrinkage methods (for example, LASSO).4 These methods are based on choosing models with the best in-sample fit as measured by statistical tests (such as F and t-tests), statistical criteria (such as mean-squared error, adjusted R2, information criteria, or Mallows' C), and statistical stopping rules (for example, p-values indicate if a variable stays in the model or is excluded).
Each variable selection algorithm has its advantages and disadvantages. Subset selection considers all possible models (good and bad) with various combinations of potential drivers and selects models that satisfy predetermined criteria. This increases the variance of the subset method relative to stepwise and LASSO, which follow certain paths in choosing an optimal model. At the same time, the subset selection is the least biased because it selects a model that globally optimized predetermined criteria. This might not be true for stepwise and LASSO.5 However, this advantage comes at a cost – subset selection is a computationally intensive algorithm. As the number of variables increases, the number of models grows exponentially (Hastie et al, 2013).6
Three Stages of Model-Building
The variable selection algorithm is only a part of the model-building process for a target risk metric. We believe that models built using pure data-mining techniques, though they may fit the historical data well, are not sufficient for regulatory compliance. Optimal models used for forecasting and stress testing should have a combination of statistical rigor and economic theory. Models built this way enjoy the additional benefit of ease of interpretation.
Our model-building consists of three stages. In the first stage, economic theory, historical correlations and graphical analysis, expert judgment, and experience with similar models guide us in the choice of potential drivers. Our choice is typically restricted to forecasts of drivers provided by the regulators, generated within Moody’s Analytics macroeconomic models, and other available risk metric models. In the second stage, these potential drivers enter the customized best-subset variable selection algorithm which may include the analyst’s expectation on the signs of coefficients, threshold p-values, and correlation between drivers. The output of the second stage is a list of ranked models from which one can select the optimal model. The final stage involves the diagnostics and validation of the optimal model selected in the second stage. We analyze the forecasts, run post-estimation diagnostics, and perform back-testing and sensitivity analysis.
Figure 1 Visualization of the dependence of the number of models on the numbers of potential and final drivers. Illustration for m ∈ [20, 30] and k ∈ [0, 10].

Source: Moody’s Analytics
It is crucial to handle the model space properly when using the best-subset selection algorithm, as specifying many potential drivers implies a large number of candidate models. To reduce the computational burden, we use a supporting dataset with the binary representations of the potential models. This significantly reduces the computation time because the potential models do not have to be generated “on the fly.” Also, we can achieve a significant reduction of the model space by setting a ceiling on the maximum number of variables in the resulting models. In Figure 1, we show the number of models as a function of the number of potential drivers m and the number of final drivers k, such that k ≤ m.
Selection and Ranking Criteria
Figure 2 illustrates the customized variable selection algorithm. Given the set of potential models, an analyst can choose to exclude models with highly correlated drivers to avoid the adverse effects of multicollinearity (Greene, 2012).7 The selection criteria, which include analysis of the signs of the coefficient estimates and their statistical significance, can be used to eliminate models that do not comply with prior expectations. In this case, once all the potential models are estimated, those with statistically insignificant coefficients and “wrong” signs can be disregarded depending on the problem setup. These criteria help us narrow the model space to include only relevant models that will be analyzed further.8
Figure 2 Customizable variable selection algorithm

Source: Moody’s Analytics
The next step is to rank the remaining models according to the ranking criteria. A large number of criteria exist to evaluate regression models used in the context of variable selection. Traditionally, the ranking of models is based on in-sample fit, which is a measure of the distance of fitted values to actual historical series. In addition, the forecast properties of the models should be considered. The adjusted R2 compensates for the fact that the inclusion of more drivers produces larger R2 even when the extra variables are irrelevant. In addition to this relative measure of fit, we also calculate an absolute measure, the root mean squared error (RMSE). Since the main purpose of the model is forecasting, the ratio of adjusted R2/RMSE is one of the most important ranking criteria, with higher values indicating better fit. Other measures such as the information criteria impose a heavier penalty on model complexity, applying different punishments for the inclusion of additional variables.9
Validation
In addition to measures of in-sample fit, we also consider a model’s predictive performance since a good in-sample fit does not imply good forecast properties. Recent academic work has seen a surge in computationally expensive validation methods. In general, historical data are split into estimation (training) and validation (hold-out) subsamples. To assess the forecast properties of a model, one has to compare its forecast values and actual realizations. For example, the predictive accuracy of a model can be measured by the mean squared error on the hold-out samples. A complementary technique is stability analysis, in which coefficient estimates on hold-out samples are tested for their equality with the estimates obtained on a complete dataset.
One way to split the data for validation is to subsequently remove the most recent observations. However, there are often not enough data for extensive back-testing since the sample size could be too small to be a reliable indicator of future forecasting performance. Alternative versions of defining training/hold-out subsamples are leave-one-out, k-fold cross-validation, and bootstrapping. We typically perform fivefold validation as it is shown empirically to have prediction error rates that suffer neither from excessively high bias nor from very high variance.10
To perform cross-validation, we first split the historical data into five non-overlapping windows. Each iteration will have a time-ordered training subset and an adjacent validation subset. The variable selection algorithm is run on the training data to select the optimal model. The selected model is used to create a forecast for the validation subset. The cross-validation root mean squared prediction error and its confidence intervals are then computed to assess the predictive ability of the model.
Finally, we perform a sensitivity analysis of the model. We look at the impulse responses of the target risk metric to each driver and standardized coefficient estimates. For impulse response analysis, a shock occurs only in one driver at a time since the shocks in different drivers are independent and the model is used to forecast the dependent variable.
Stationarity and Cointegration
In market risk applications, it is very common to deal with non-stationary variables. Empirical modeling faces difficulties when time series are non-stationary in that the means and variances of outcomes change over time. If unrelated time series are non-stationary due to past shocks of different origins, their correlation is still likely to appear significant, generating nonsensical relations. With wrongly assumed stationarity, the uncertainty is underestimated, affecting accuracy and precision of the forecasts. If appropriately handled, however, non-stationary variables can help to elucidate long-run relationships in the data.
Formally, the Box-Jenkins methodology to model time series requires both dependent and independent variables to be stationary. If this requirement is unmet and the variables are integrated of different orders – for example, one is stationary I(0) and one is non-stationary I(1), or vice versa – this is a case of spurious regression. If both variables are integrated of the same order (typically I(1)) there are two possibilities. If there exists a linear combination of the variables that is I(0), the variables are cointegrated. The cointegrated variables share the same stochastic trends and the ordinary least squares (OLS) coefficient estimates are super-consistent.11 If the two variables are not cointegrated, the regression is spurious.
When specifying a model, a natural approach would be to pre-test the target risk variable and drivers in the regression equation for unit roots. If they are stationary, we can safely apply a classic modeling methodology. If they are non-stationary, we can either transform the data to induce stationarity or check if they are cointegrated. We typically prefer the latter approach, as data transformations are often problematic in terms of interpretation and intuition behind the link between the variables.12 To test for cointegration, variables in the model need to be of the same order of integration. If they are, then we can further test for cointegration using Johansen and Engle-Granger types of tests.13
One should be careful, however, when interpreting the results of stationarity and cointegration tests in finite short samples. These tests have low power in distinguishing highly persistent stationary series from non-stationary processes and they work better for longer time frames. So, 15 years of quarterly data (60 observations) is better than five years of monthly data (60 observations). For time series models, we typically work with a short time frame. Also, the presence of structural breaks makes it difficult to distinguish a non-stationary series from stationary data around a break. Thus, a thorough examination of data followed by a combination of different tests is suggested as a way to eliminate some of these shortcomings.14
Variable Selection Examples
We illustrate how to apply our model-building procedure to specific problems based on actual client projects. In addition, we evaluate the results of different variable selection algorithms. In our exercise, we focus on stress testing of market risk metrics for regulatory and Moody’s Analytics internal scenarios. The market risk metrics are the rating structure of the US corporate spreads and the term structure of the UK government bond yields.15 We consider PRA 2016 scenarios (baseline and stress), Comprehensive Capital Analysis and Review (CCAR) 2016 scenarios (baseline and severely adverse), and two Moody’s Analytics scenarios (baseline and protracted slump).
The regulators explicitly prescribe the timing and magnitude of the response of a risk metric to a shock. To satisfy these requirements, the stress testing models must follow the prescribed paths of the exogenous variables provided by the regulators. The inclusion of lag structure in the models might change the timing and magnitude of the shock in the risk metric. For example, ARIMA(p, q) might not deliver sufficient stress if the period of the hypothesized shock is preceded by tranquility in the historical data. To avoid possible inconsistencies with the prescription of the regulators, we typically limit the use of lag structure in the figures that follow, although the algorithm is flexible enough to incorporate it.
The target risk metric is a term or rating structure whereby the variations across various maturities and ratings are observed over time. We first focus on reducing the dimension of the cross-section units to a smaller number of underlying factors. To model the term structure, we follow a modified Nelson-Siegel approach. First, we obtain the forecasts on the level and slope. 16
Second, the forecasts of the key maturities, such as 1- and 10-year, are built back from the level and slope. Finally, the forecasts of all the remaining maturities are obtained by interpolation between the key maturities based on their historical ratios. This approach properly aligns maturities and is also robust to possible curve inversions in the stress scenarios.
In the first stage of model-building, we select potential drivers guided by economic theory, historical data correlations, and our experience with similar models. The list of potential drivers considered for the three groups of market risk metrics is shown in Figure 3. These drivers have forecasts from the Moody’s Analytics macroeconomic country model or a regulator. In the actual client project our list had more variables, but we have shortened the list to keep the presentation manageable. In the second stage, we run automatic yet flexible and interactive algorithms to select variables for inclusion in the model from the pool of potential drivers.
Global factors are included in the list of potential drivers to maximize the informative content of core macro and financial drivers. They reduce the dimensional space of the explanatory variables, thus achieving more parsimony and flexibility. Principal component analysis is used to extract relevant business cycle information from the sets of macroeconomic variables. The key factors include global measures of growth, equity, and volatility. Each of these factors represents a variation from a wide range of constituent macro and financial variables as well as geographical territories. Global growth factor captures the dynamics of global economic activity and is an aggregate measure of the real GDP growth of key world economies.
Figure 3 List of potential drivers

Source: Moody’s Analytics
In the second stage of model-building, we run automatic yet flexible and interactive algorithms to select variables for inclusion in the model from the pool of potential drivers. We consider best subset selection, forward and backward stepwise, and LASSO to choose a best model for the principal components of the UK bond term structure and the corporate spread rating structure.17 In the best subset selection algorithm, we restrict our attention to models with a maximum number of drivers allowed in the models to k={max{3,max{klasso,kstepwise}}, where klasso and kstepwise are the number of drivers in the optimal model selected by LASSO and stepwise algorithms, respectively. In actual client projects, we typically use the best subset selection algorithm, while here we compare results of alternative variable selection methods.
Stress Testing the Corporate Spreads Rating Structure
The rating structure consists of seven ratings depicted in Figure 4. The curves are aligned across ratings and the spreads widen during periods of economic downturns and market uncertainty, including the dot-com bubble around 2002 and global financial crisis in 2008. High yield corporate bonds exhibit wider spreads and display more variation than those with investment grade ratings. The rating structure does not have inversions or crossovers.
Figure 4 Historical data on Bank of America Merrill Lynch (BAML) corporate spreads by rating

Source: Federal Reserve Bank of St. Louis
We first forecast the level and slope components extracted from the rating structure. We then obtain the forecasts of the lower rating C and upper rating AAA based on the two components. Finally, we interpolate the remaining ratings based on the historical distance to lower and upper adjacent ratings.
For the level equation, the optimal model has two drivers, namely the global equity factor (GEF) and the US average A corporate spread based on the ratio adj.R2/RMSE and cross-validation criteria. The model based on the information criteria has three drivers, slightly lower adj.R2/RMSE ratio and cross-validation error, although largely overlapping confidence intervals. The model selected by the stepwise and LASSO algorithms has worse in-sample fit and predictive ability, as shown in Figure 5. For the slope equation (Figure 6), the optimal model has three drivers: the US 10-year government bond yield, GEF, and global equity volatility factor (GEVF). This model is superior to the one selected by the stepwise and LASSO based on both in-sample fit and cross-validation statistics.
Figure 5 Selected models for level of rating structure

Source: Moody’s Analytics
Figure 6 Selected models for slope of rating structure

Source: Moody’s Analytics
Forecasts of the rating structure across the scenarios are shown in Figure 7. They are consistent across ratings and exhibit spreads wider under the CCAR than under PRA or Moody’s Analytics stress scenario.
Figure 7 Forecasts of BAML corporate spreads by rating
Click on image to see a detailed version
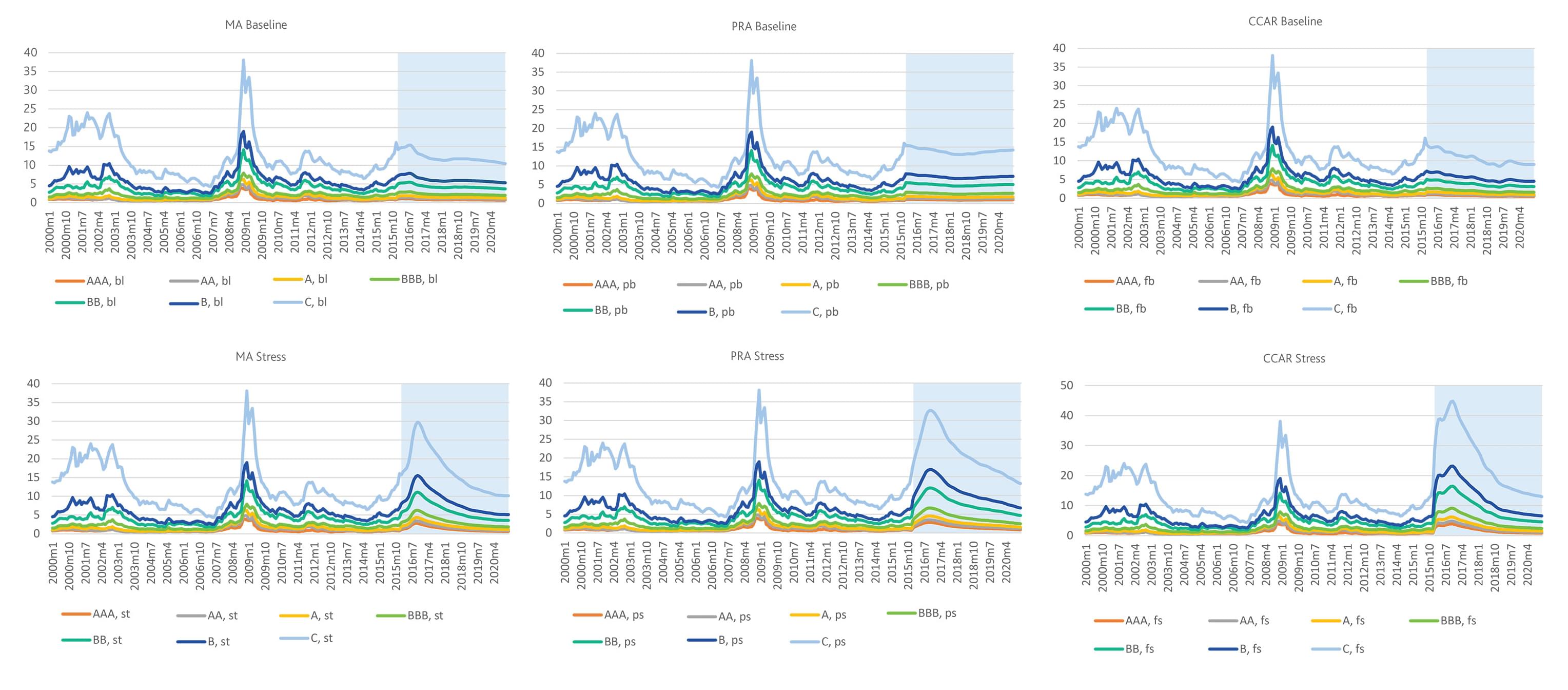
Source: Federal Reserve Bank of St. Louis historical, Moody’s Analytics forecasts
UK Government Bond Yields
The UK government bond yield term structure consists of 19 maturities, shown in Figure 8. Sharp upswings in the short-term rates reflected the Central Bank controlling tight-money policies. In this expansionary period, the spread between short- and long-term rates is very narrow. Following the peak in 2008, short-term rates fell sharply with economies in recession and policy rate cuts, while the longer-term rates formed a relatively smoother downtrend. This created a wider spread between short- and long-term rates, increasing sharply the slope of the swap rate curves, that is, the difference between the long- and short-term rates. To model this term structure, we first forecast the level and slope components. Second, the key maturities are modeled with level and slope added to the list of potential drivers. Lastly, the rest of the maturities are interpolated in between the key maturities.
Figure 8 Historical series of UK government bond yields

Source: Moody’s Analytics
Figure 9 and Figure 10 contain the estimation results of the key maturities. For the three-month bond yield, the optimal model includes the level and slope. This model has the best in-sample fit as measured by adj.R2/RMSE and Bayesian information criterion (BIC) as well as the lowest cross-validation RMSE. Notably, despite the fact that the model selected by the stepwise and LASSO shows better in-sample fit and predictive ability than the optimal model, it suffers from collinearity. The mean variance inflation factor (VIF) indicates the presence of multicollinearity. This model was not considered in the best subset selection algorithm since the maximum allowed correlation between drivers is set at 0.85. The optimal equation for the slope includes the level, slope, and volatility.
Figure 9 Selected models for UK three-month government bond yield

Source: Moody’s Analytics
Figure 10 Selected models for UK five-year government bond yield

Source: Moody’s Analytics
Forecasts of the term structure of the bond yields are depicted in Figure 11. The longer-term rates increase in stress in PRA scenarios while they decline in Moody’s Analytics and CCAR stress scenarios, since the UK is regarded as a safe haven.
Figure 11 Forecasts of GBR government bond yields
Click on image to see a detailed version

Source: Moody’s Analytics historical and forecasts
Concluding Remarks
This article presents the methodology we use to build stress testing models for target market and credit risk metrics. This framework is highly flexible to accommodate various increasing regulatory demands and also classical forecasting practices. This is done by customizing the model selection algorithm in line with analysts’ prior expectations and assumptions.
The three-step methodology combines economic intuition and a customized best-subset selection algorithm to find the optimal parsimonious model with good in-sample fit, forecast properties, and consistency with regulatory assumptions. The model developer can be involved in every step of model-building, from selecting the pool of potential drivers to customizing the variable selection algorithm and choosing the optimal model from the list of potential models ranked according to predefined criteria.
Further, this methodology is applied to two types of market risk instruments. We demonstrate that this approach is most suitable for our purposes compared with alternative procedures. In our examples, we find some differences between the optimal combination of drivers selected by the best subset, stepwise, and LASSO approaches, although the selected models have similar predictive ability and in-sample fit. The optimal models selected by stepwise and LASSO are in the range of the 10 best models as ranked by the best subset selection.
Notes
1 In response to regulatory requirements, typical stress testing models have a limited dynamic structure to avoid shifting the timing of the shock response; the models are required to identify a significant correlation between macroeconomic variables and risk metrics.
2The variable selection methodology described in this paper is also applicable to stress testing of portfolio credit risk with some adjustments for panel data.
3The optimal model selected by the algorithm usually provides adequate consistency with regulatory assumptions on drivers, as well as sufficiently good in-sample fit and forecasting properties. However, in rare cases, the best model can produce insufficient or excessive stress relative to its own history or the stress observed in drivers, or it can be in non-compliance with targets provided by regulators.
4The literature on this topic is enormous. Gareth et al (2015), Hastie et al (2013), and Miller (2002) provide a general overview of the methods.
5The discussion is based on the assumption that the vector of potential drivers contains true variables that were used in the data generating process. See Miller (2002) for a discussion on bias in variable selection.
6For example, to select the best model from just 10 drivers, one has to consider 1024 models (=210). Adding an additional driver doubles the number of models to be considered.
7This step is optional and can be omitted if the structural analysis is not the primary goal. Notably, the collinear variables themselves are not removed from the further analysis and each of them can be a part of another model.
8For hypothesis testing, it is important to obtain a consistent estimator of variance-covariance matrix. In market risk applications, we use the Newey-West estimator robust to autocorrelation of lag p and arbitrary form of heteroskedasticity (Newey and West, 1987). In credit risk applications, one has to account for potential correlation of error terms within clusters. See Cameron and Trivedi (2010) for univariate and multivariate clustering.
9Each of the ranking criteria can be formalized for linear models (in terms of residual sum of squares (RSS)) and non-linear models (in terms of the value of a likelihood function). Gareth et al (2015) and Lindsey and Sheather (2010) provide formulas and intuition behind these criteria; Pawitan (2001) shows the asymptotic properties of these performance metrics.
10For detailed discussion on this, see Gareth et al (2015), ch. 5.1.4.
11If the variables are cointegrated the OLS estimates from the regression converge to the true value with N-1 and not only N-1/2 as usual OLS estimates do.
12This is especially important in the context of stress testing where the variables of interest should be linked to explanatory variables provided by a regulator in a given format. Even if non-stationarity is confirmed by a number of tests, it is often recommended against differencing or any other transformation to make the series stationary. This is because the differencing discards information concerning co-movements in the data. In deterministic stress testing, it is crucial to keep these co-movements.
13Enders (2003) provides extensive description of cointegration and stationarity tests.
14When the data are rich enough to rely on the stationarity tests, we use augmented Dickey-Fuller (ADF) and Phillips-Perron (PP) tests with the null hypothesis being non-stationarity, and Kwiatkovski-Phillips-Schmidt-Shin (KPSS) test using stationarity as the null hypothesis. KPSS test was originally designed to address the low power of the ADF test. This approach allows us to look from both sides by transposing the stationarity hypothesis. For example, when a near non-stationary time series is found non-stationary with ADF test, it can be found stationary using the KPSS test. When these tests result in mixed evidence further analysis is needed to draw conclusions, such as looking for possible structural breaks or trying other test specifications.
15All the data are publicly available. The corporate spread data were downloaded from Federal Reserve Economic Data (FRED), and the UK bond data are from Reuters.
16Level and slope are the first and second principal components obtained from the eigenvalue decomposition performed on the covariance matrix of the term structure. This makes the PCA components comparable to the underlying tenors in terms of measurement units.
17The potential issue of multicollinearity is not explicitly addressed in stepwise. This often results in expected signs violations when two or more drivers that are not independent are included in the model.
References
Bocchio, Cecilia, Dr. Juan M. Licari, Dr. Olga Loiseau-Aslanidi, Dr. Ashot Tsharakyan, and Dr. Dmytro Vikhrov. "Stressed Scenarios and Linkages to Market Risk Instruments." Moody's Analytics methodology. December 2015.
Cameron, A. Colin and Pravin K. Trivedi. Microeconometrics Using Stata. College Station: Stata Press. 2010.
Enders, Walter. Applied Econometric Time Series. Wiley. 2003.
Friedman, Jerome, Trevor Hastie, Simon Noath, and Rob Tibshirani. "Package 'glmnet.'" R Help File on glmnet. 2016.
Furnival, Gerge, and Robert Wilson. "Regressions by Leaps and Bounds." Technometrics 16 (4): 499-511. 1974.
Gareth, James, Daniels Witten, Trevor Hastie, and Robert Tibshirani. An Introduction to Statistical Learning with Applications in R. New York: Springer. 2015.
Greene, William. Econometric Analysis. Upper Saddle River: Prentice Hall. 2012.
Hand, David. "Branch and Bound in Statistical Data Analysis." The Statistician 30 (1). 1981.
Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. The Elements of Statistical Learning. 2nd. New York: Springer. 2013.
Hughes, Tony, and Poi Brian. "Multicollinearity and Stress Testing." Moody's Analytics Risk Perspectives. May 2015.
Kaminsky, Graciela, and Carmen Reinhart. "On crises, contagion, and confusion." Journal of International Economics 51 (1): 145-168. 2000.
Licari, Dr. Juan M., Dr. Olga Loiseau-Aslanidi, and Dr. José Suárez-Lledó. "Modeling and Stressing the Interest Rates Swap Curve." Moody's Analytics Risk Perspectives. October 2013.
Lindsey, Charles, and Simon Sheather. "Variable selection in linear regression." The Stata Journal 10 (4): 650-669. 2010.
Longstaff, Francis. "The subprime credit crisis and contagion in financial markets." Journal of Financial Economics 97 (3): 436-450. 2010.
Miller, Alan. Subset Selection in Regression. 2nd. New York: Chapman & Hall. 2002.
Newey, W.K., and K.D. West. "A simple positive-definite, heteroskedasticity and autocorrelation consistent covariance matrix." Econometrica 55 (3): 703-708. 1987.
Pawitan, Yudi. In All Likelihood: Statistical Modelling and Inference Using Likelihood. Oxford: Clarendon Press. 2001.
Poi, Brian. "Choosing Explanatory Variables in Linear Regression Models." Moody's Analytics whitepaper. 2015.
Featured Experts

James Partridge
Credit analytics expert helping clients understand, develop, and implement credit models for origination, monitoring, and regulatory reporting.

Tomer Yahalom
Insurance enterprise risk researcher; credit portfolio modeling expert

Jun Chen
A well-recognized researcher in the field; offers many years of experience in the real estate finance industry, and leads research efforts in expanding credit risk analytics to commercial real estate.
As Published In:

Examines the role of disruptive technologies in the financial sector and how firms can improve their practices to remain competitive.
Previous Article
Modeling and Forecasting Interest Rate Swap SpreadsRelated Articles
Forecasting Credit Risk for the Cruise Industry: Can It Get Worse in the Asia-Pacific?
Over the past two years, the cruise industry in the Asia-Pacific has seen a surge in corporate credit risk, pushing several companies to default. Using Genting HK as an example, we demonstrate analytics in action by capturing deteriorating credit risk 20 months prior to the firm’s liquidation filing.
Using ESG Score Predictor: A methodological framework to estimate ESG scores
ESG Score Predictor models provide an analytical solution for generating a wide range of comparable and standardized metrics for assessing the potential degree to which companies take into account and manage ESG and climate risks.
Embedding Interest Rate Risk into Stress Testing: Macroeconomic Scenarios in Behavioral Models
This paper provides an analytical approach to designing macroeconomic scenarios and behavioral models for measuring the interest rate risk in the banking book (IRRBB).
ESG Score Predictor: Applying a Quantitative Approach for Expanding Company Coverage
Assessing Environmental, Social, Governance (ESG) and climate risk is often subject to data constraints, including limited company coverage. This paper provides an overview of Moody’s ESG Score Predictor, an analytical framework that can expand coverage gaps by generating a wide array of ESG and climate risk metrics.
Climate Risk Macroeconomic Forecasting - Executive Summary
This paper describes Moody's Analytics approach to generating climate risk scenarios.
Global Economic Outlook: December 2020
Presentation slides from the Council of the Americas CFO Forum of 2020.
Continued Stress of the UK Mortgage Market
We use the UK Mortgage Portfolio Analyzer to assess the adverse economic impact from of the global pandemic on a representative portfolio of the UK mortgages.
Automating Interpretable Machine Learning Scorecards
We demonstrate that the interpretable benchmark model sacrifices little predictive power compared to the unconstrained challenger models.
COVID-19: Living Through the Stress Test of the U.K. Mortgage Market
We use the Moody's Analytics Mortgage Portfolio Analyzer to quantify the impact of this significant economic stress on a portfolio of U.K. mortgages.
Analytical Solutions for Multi-Period Credit Portfolio Modelling
A framework for credit portfolio modelling where exact analytical solutions can be obtained for key risk measures such as portfolio volatility, risk contributions to volatility, Value-at-Risk (VaR) and Expected Shortfall (ES).




